Below is a detailed description of some of the research that I have worked on. Google scholar should have a regularly updated list, found here.
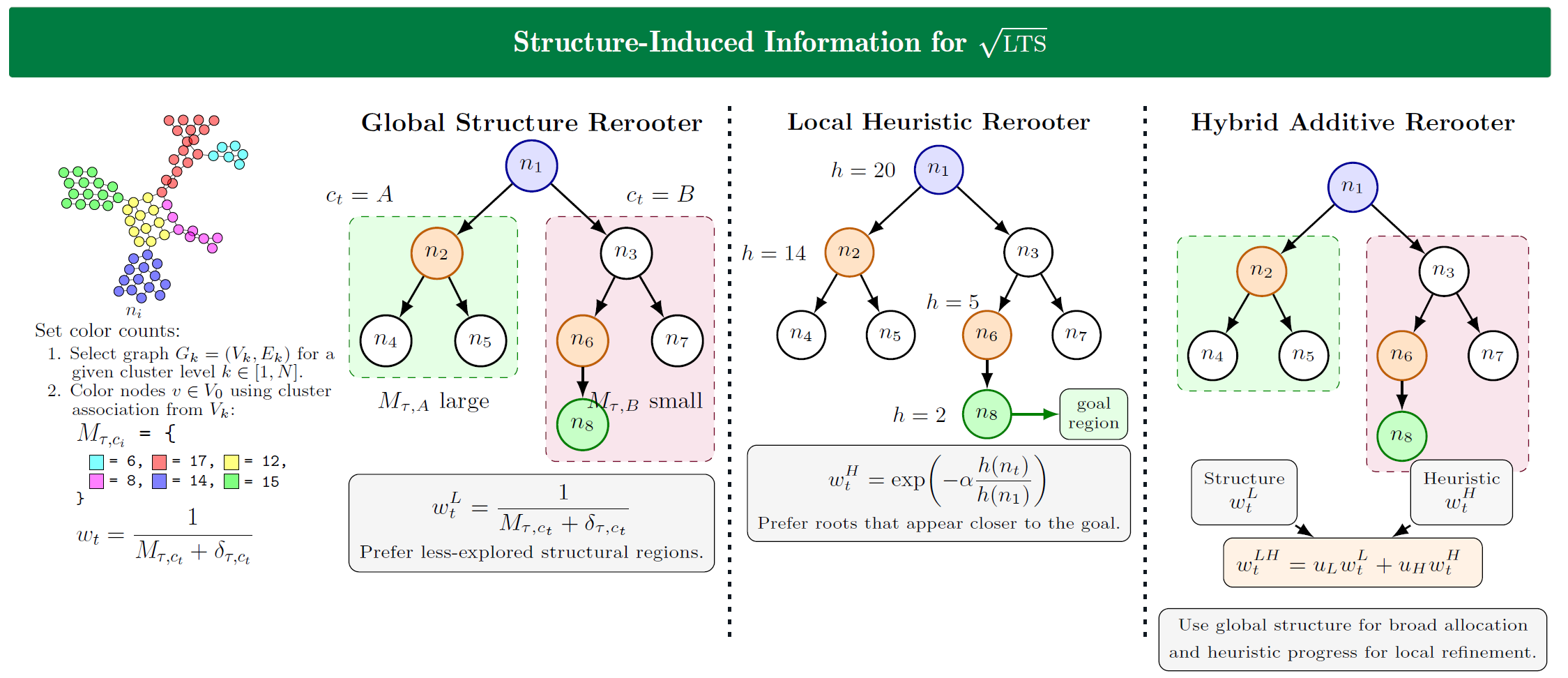
Structure-Induced Information for Rerooting Levin Tree Search
This paper introduces new ways to improve policy-guided tree search for difficult single-agent planning problems. The paper focuses on
The results show that these rerooting methods can scale to complex domains where prior subgoal-based search methods struggle, while achieving strong online training efficiency across environments such as BoulderDash, CraftWorld, Sokoban, and a gridworld Traveling Salesman Problem. Overall, the work demonstrates that useful structural information can be extracted directly during search, enabling more efficient allocation of computation without relying on expensive subgoal reconstruction models.
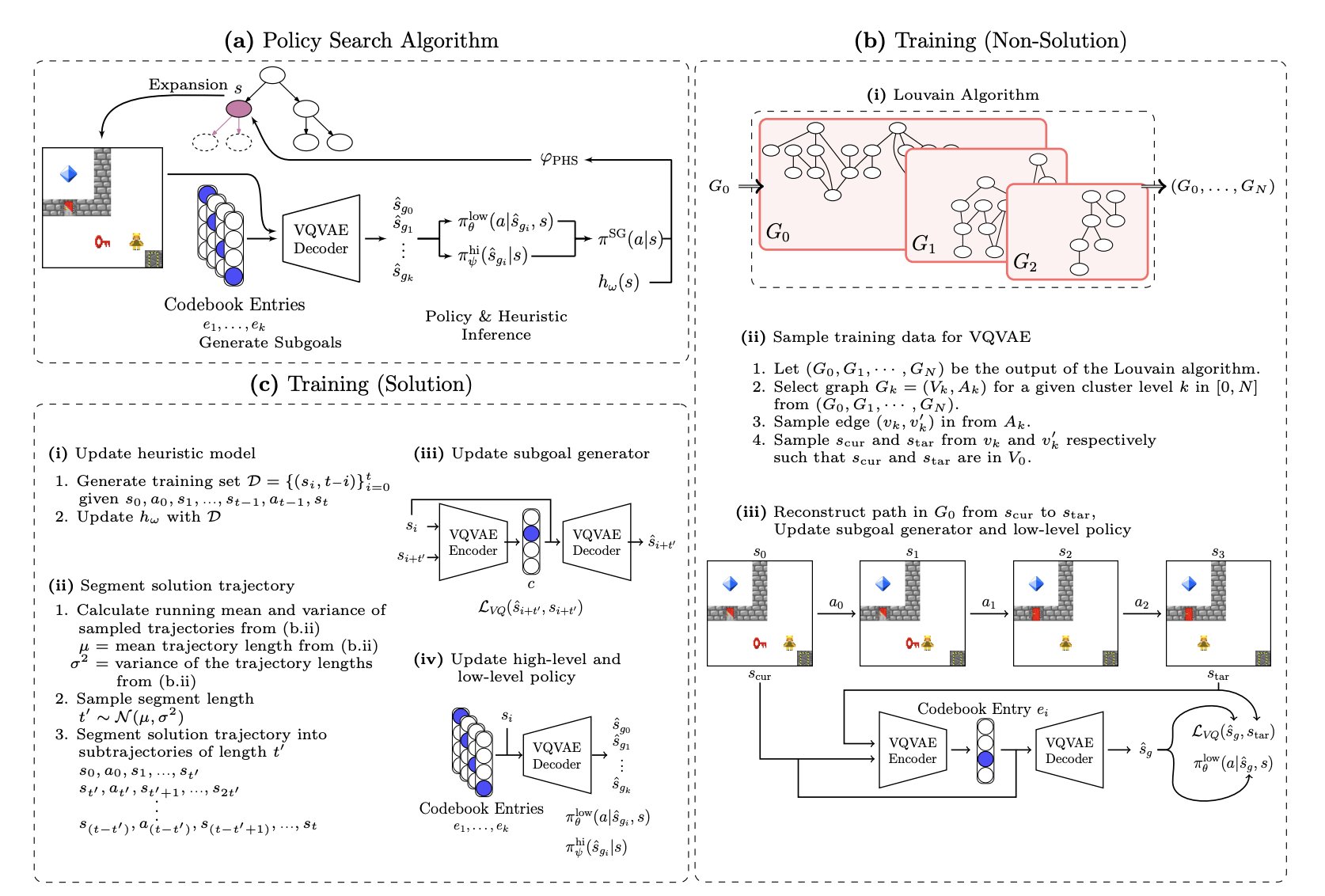
Subgoal-Guided Policy Heuristic Search with Learned Subgoals
This paper looks at a class of algorithms called policy tree search, which combines policies from reinforcement learning with traditional tree search. We show how one can decompose a problem into learnable subgoals, without any prior knowledge of the environment. This enables our method to learn from failed attempts where we do not solve the problem outright, but solve some of the subgoals. The results show that this approach helps the system learn faster and more efficiently, without sacrificing the quality of the policy.

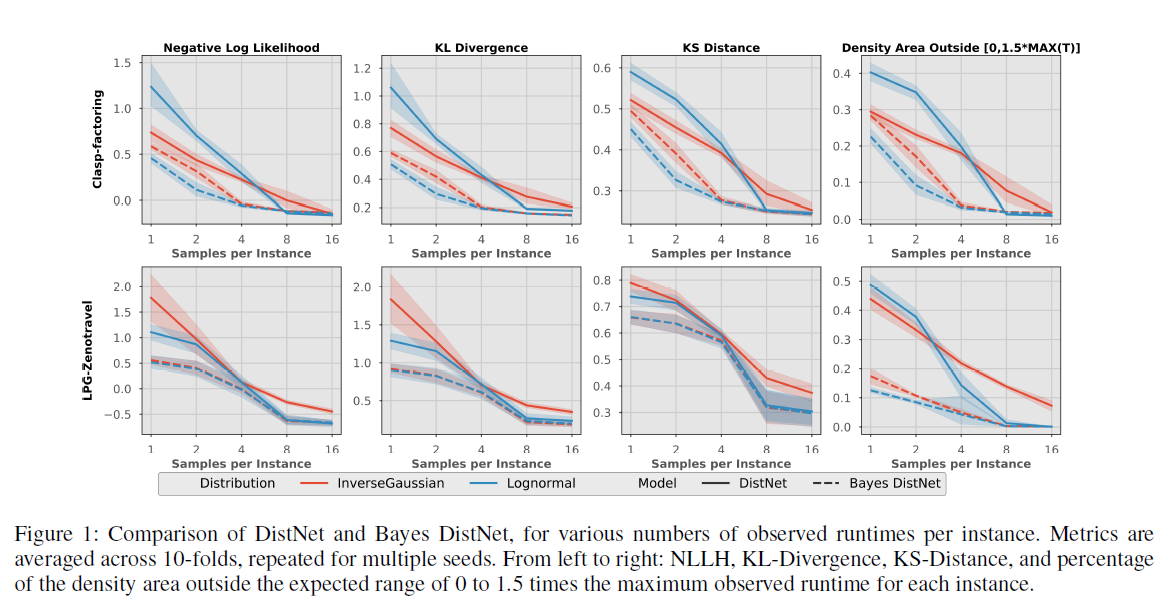
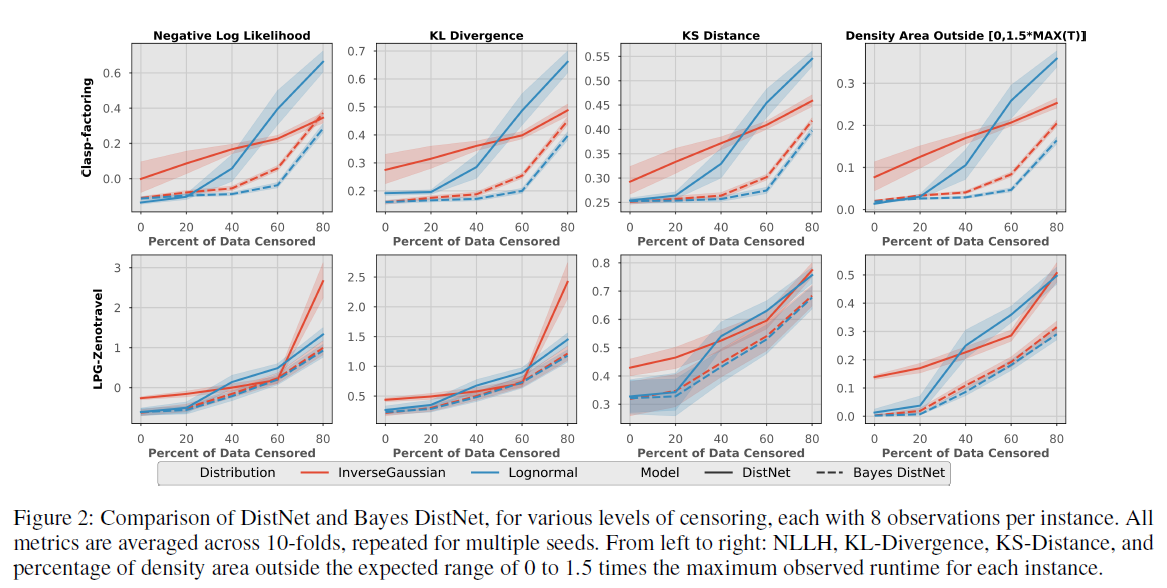
Bayes DistNet - A Robust Neural Network for Algorithm Runtime Distribution Predictions (AAAI-21)
Many of the algorithmic solvers for NP-complete problems rely on backtrack methods with added randomness/restarts (to help alleviate some of the heavy-tail nature that the runtimes exhibit when they traverse down eventual dead-ends in the search tree). Introducing randomness into the solvers means that a given algorithm ran on the same input problem follows some unknown distribution. Portfolio solvers use a collection of different algorithms, and tries to assign the algorithm technique which would solve the given input the fastest. Knowing the RTDs of each algorithm in the portfolio allows such solvers to choose the best algorithm for a given problem instance.
The tradition state-of-the-art model DistNet jointly learns the parameters of the RTD by using a neural network, with one output for each parameter of the distribution. For example, if we assume the RTD follows a Normal distribution
We extend DistNet into the Bayesian setting using Bayesian neural networks (BNN), calling it Bayes DistNet. Instead of using pointwise weights in the network, BNNs have a prior distribution over its weights and uses posterior inference. Since the posterior is an intractable calculation, variational methods are used to construct an approximation to the distribution. Finally, our model has a single output which is the predicted runtime. By using the same input to our model multiple times, different runtimes will be predicted and combining them will produce a predicted runtime distribution.
We show that our model Bayes DistNet is able to predict distributions that more closely resemble the true runtime distribution when the number of training samples are small, or when there are censored examples (only lower bounds on the actual runtime are known, as the algorithm took too long and had to prematurely stop). Our model is also able to give its uncertainty on its predictions.
Chromatic Symmetric Functions and H-free Graphs (Graphs and Combinatorics - Springer)
This paper studies a problem at the intersection of graph theory and algebraic combinatorics: how the structure of a graph influences the algebraic properties of its colorings. A classical graph coloring asks whether the vertices of a graph can be assigned colors so that adjacent vertices receive different colors. The chromatic symmetric function is a richer version of this idea: instead of only counting colorings, it records more detailed information about how colors can appear across the graph. A central question is whether this function has a “positive” expansion in certain natural algebraic bases, which often indicates that the graph has hidden combinatorial structure.
The motivation comes from two major conjectures about claw-free graphs, which are graphs that do not contain a simple three-pronged “claw” pattern as an induced subgraph. These conjectures suggest that forbidding the claw may force the chromatic symmetric function to behave in especially nice ways. In this paper, we ask how far that idea can be extended: if we forbid the claw together with one additional four-vertex graph, when does every graph in the resulting class have an
We classify nearly all of these cases. Some forbidden-pattern pairs guarantee