Normalizing Flows
Normalizing flows learn a probability model by transforming a simple distribution into a more complicated one using a deep network. Normalizing flows can both sample from this distribution and evaluate the probability of new examples. However, they require specialized architecture: each layer must be invertible. In other words, it must be able to transform data in both directions.
1D Case
Consider modeling a 1D distribution
Measuring Probability
Measuring the probability of a data point is more challenging. Consider applying a function
More precisely, the probability of data
where
Forward and Inverse Mapping
To draw samples from the distribution, we need the forward mapping
The forward mapping is sometimes termed the generative direction. The base density is usually chosen to be a standard normal distribution. Hence, the inverse mapping is termed the normalizing direction since this takes the complex distribution over
Learning
To learn the distribution, we find parameters
where we assume that the data are independent and identically distributed in the first line and used the likelihood definition from Equation 1 in the third line.
General Case
Consider applying a function
- drawing a sample
from the base density, and - passing this through the neural network so that
.
The likelihood of a sample under this distribution is
where
Forward Mapping with a Deep Neural Network
In practice, the forward mapping
The inverse mapping (normalized direction) is defined by the composition of the inverse of each layer
The base density
The Jacobian of the forward mapping can be expressed as
where we have overloaded the notation to make
The absolute determinant of the Jacobian of the inverse mapping is found by applying the same rule to Equation 5. It is the reciprocal of the absolute determinant in the forward mapping.
We train normalizing flows with a dataset
where
Desiderata for Network Layers
The theory for normalizing flows is straightforward. However, for this to be practical, we need neural network layers
- Collectively, the set of network layers must be sufficiently expressive to map a multivariate standard normal distribution to an arbitrary density.
- The network layers must be invertible; each must define a unique one-to-one mapping from any input point to an output point (a bijection). If multiple inputs were mapped to the same output, the inverse would be ambiguous.
- It must be possible to compute the inverse of each layer efficiently. We need to do this every time we evaluate the likelihood. This happens repeatedly during training, so there must be a closed-form solution or a fast algorithm for the inverse.
- It also must be possible to evaluate the determinant of the Jacobian efficiently for either the forward or inverse mapping.
Inverse Network Layers
We now describe different invertible network layers or flows for use in these models. We start start with linear and elementwise flows, as they are easy to invert and its possible to compute the determinant of their Jacobians, but neither is sufficiently expressive to describe arbitrary transformations of the base density. However, they form the building blocks of coupling, autoregressive, and residual flows, which are all more expressive.
Linear Flows
Definition (Linear Flow)
A linear flow has the form
. If the matrix is invertible, the linear layer is invertible.
For
- Diagonal matrices require only
computation for the inverse and determinant, but the elements of do not interact. - Orthogonal matrices are more computationally efficient, but they do not allow scaling of the individual dimensions.
- Triangular matrices are more practical, are invertible in
.
One way to make a linear flow that is general, efficient to invert, and for which the Jacobian can be computed efficiently is to parametrize it directly in terms of the LU decomposition. In other worse, use
where
Caution
Linear flows are not sufficiently expressive. When a linear function
is applied to a normally distributed input, the result is also normally distributed. Hence, it is not possible to map a normal distribution to an arbitrary density using linear flows alone.
Elementwise Flows
Definition (Elementwise Flows)
The simplest nonlinear flow are elementwise flows, which apply a pointwise nonlinear function
with parameters to each element of the input so that The Jacobian
is diagonal since the th input to only affects the th output. Its determinant is the product of the entries on the diagonal, so
The function
where the parameters
Caution
Elementwise flows are nonlinear but do not mix input dimensions, so they cannot create correlations between variables. When alternated with linear flows (which do mix dimensions), more complex transformations can be modelled. However, in practice, elementwise flows are used as components of more complex layers like coupling flows.
Coupling Flows
Definition (Coupling Flows)
Coupling flows divide the input
into two parts so that and define the flow as Here,
is an elementwise flow (or other invertible layer) with parameters that are themselves a nonlinear function of the inputs . The function is usually a neural network of some kind and does not have to be invertible.
The original variables can be recovered as
If the function
The inverse and Jacobian can be computed efficiently, but this approach only transforms the second half of the parameters in a way that depends on the first half. TO make a more general transformation, the elements of
For structured data like images, the channels are divided into two halves
Multi-Scale Flows
In normalizing flows, the latent space
In the generative direction, multi-scale flows partition the latent vector into
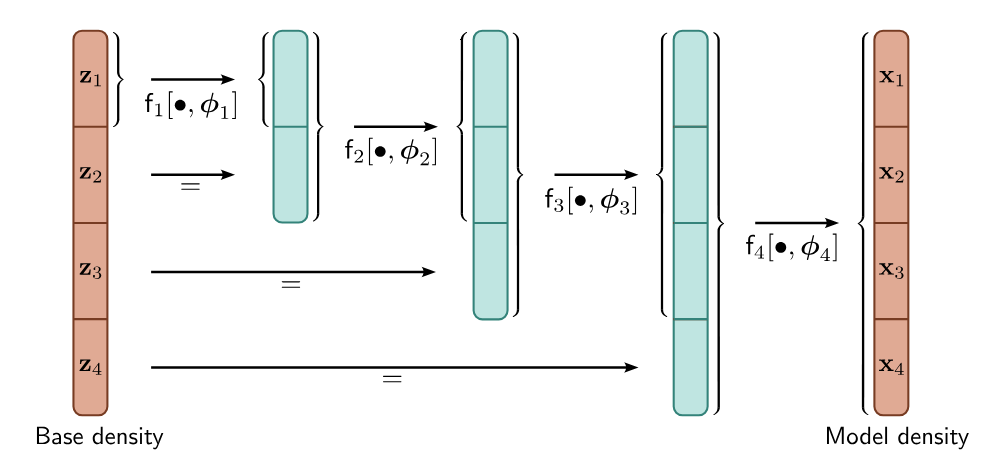
For the inverse process, the black arrows are reversed, and the last part of each block skips the remaining processing.
TODO
- Autoregressive flows, inverse autoregressive flows, residual flows,
Sources
- Prince, S. (2023). Understanding Deep Learning. Chapter 16.