Variational Autoencoders
Like normalizing flows, variational autoencoders or VAEs are probabilistic generative models; they aim to learn a distribution
It is common to talk about the VAE as if it is the model of
Latent Variable Models
Latent variable models take an indirect approach to describing a probability distribution
Typically, the joint probability
This is a rather indirect approach to describing
Nonlinear Latent Variable Model
The previous section described the general latent variable decomposition
The nonlinear latent variable model turns this template into a concrete generative model by choosing specific forms for the two pieces: a prior
In this model, both the data
The likelihood
When we need the value of a normal density at a particular point, we write this as
The function
With these choices, the joint distribution factors into the same conditional form as before:
The data probability
Intuition
This can be viewed as an infinite weighted sum (i.e. an infinite mixture) of spherical Gaussians with different means, where the weights are
and the means are the network outputs .
Generation
A new example
Training
To train the model, we maximize the log-likelihood over a training dataset
where
Caution
This objective is intractable. There is no closed-form expression for the integral and no easy way to evaluate it for a particular value of
.
Evidence Lower Bound (ELBO)
The direct maximum likelihood objective fails because
To define this lower bound, we need Jensen’s Inequality and use the logarithm as the concave function:
or by writing out the expression for the expectation
Deriving the Bound
For a fixed observed data point
We then use Jensen’s Inequality for the logarithm to find a lower bound:
where the right-hand side is termed the evidence lower bound or ELBO. It gets its name because
Eventually,
The reason
To learn the nonlinear latent variable model, we maximize this quantity as a function of both
ELBO Properties
Consider that the original log-likelihood of the data is a function of the decoder parameters
The figure below separates these two effects: the left graph shows how changing
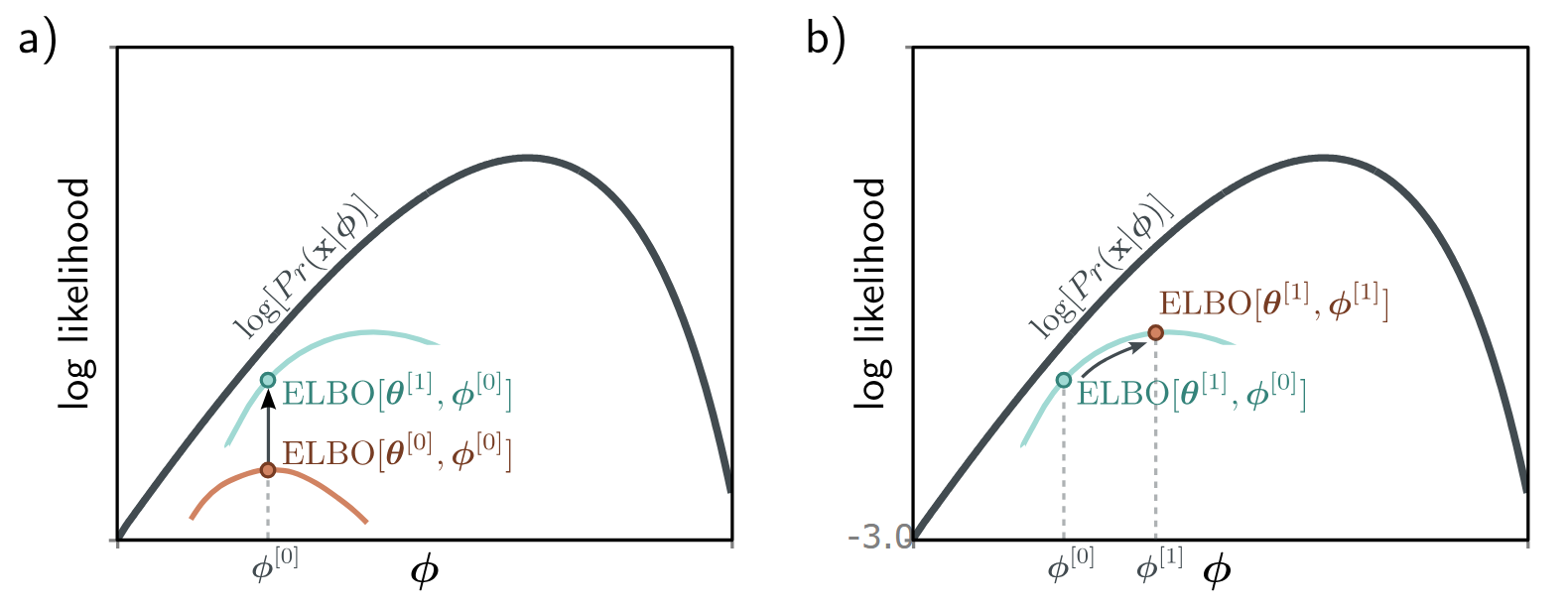
Two Views of the Same ELBO
The ELBO can be rewritten in two useful ways depending on how we factor the joint distribution
If we factor the joint as
then the ELBO becomes the true log-likelihood minus a KL divergence to the true posterior. This view explains why the bound is lower than the log-likelihood and when it becomes tight.
If we factor the joint as
then the ELBO becomes a reconstruction term minus a KL divergence to the prior. This view explains the training objective used by the VAE: decode latent samples that explain
Intuition
The first view compares the ELBO to the quantity we wish we could optimize directly,
. The second view shows how to compute and optimize the bound in practice. The first view answers “how good is the bound?” The second view answers “what pressure does the VAE training objective put on the encoder and decoder?”
Tightness of Bound
The ELBO is tight when, for a fixed value of
Here, the first integral disappears between lines three and four since
Intuition
The ELBO is the original log-likelihood minus the KL divergence between
and the true posterior . This KL divergence is the gap between the lower bound and the true log-likelihood. The KL will be zero, and the bound tight, when . This true posterior indicates which latent values could have been responsible for the observed data point.
Caution
This form explains the bound, but it cannot be used directly for training. It contains both
and the true posterior , and both require the same intractable marginal likelihood . This motivates rewriting the same ELBO in terms of the decoder likelihood and the prior.
ELBO as Reconstruction Term Minus KL to Prior
A second useful way to express the same ELBO is as a reconstruction term minus the distance to the prior:
where the joint distribution
Why This Form Helps
This version no longer contains the true posterior
or the marginal likelihood explicitly. It uses the decoder likelihood , the prior , and the chosen encoder distribution , which are terms we can compute, sample from, or approximate.
Intuition
The first term measures the average agreement between the observed data
and the decoder likelihood , where the average is taken over latent values sampled from . This is a reconstruction term because is chosen to put probability mass on latent values that plausibly explain this particular ; for each such , the decoder is rewarded when it assigns high probability to reconstructing the same . The average is not taken over the prior because the prior describes how to generate new latent variables before seeing any data, while is the data-dependent distribution over latent variables after seeing . The second term measures the degree to which matches the prior. When training by minimizing the negative ELBO, the first term becomes a reconstruction loss and the second term becomes a KL penalty.
Why Return to the Posterior View?
The reconstruction/prior form does not explicitly contain the true posterior
The posterior view tells us what
Variational Approximation
Problem: Intractable Posterior
The tightness result says that the best possible choice for
but in practice this is intractable because we cannot evaluate the term
is the prior; how plausible was this latent code before seeing is the decoder likelihood; if this were the latent code, how likely would it be to produce the observed is the posterior; after seeing , how plausible is this latent code as its explanation
Solution: Variational Family
The solution is to make a variational approximation: we choose a simple parametric family for
where
This Gaussian family will not always match the true posterior perfectly, but it may be a good approximation for some values of
Intuition
This is not a coincidence: the posterior view tells us the ideal target for
, while the reconstruction/prior view gives a tractable objective that pushes toward that target.
Amortized Inference
This also explains why we use an encoder network. In principle, each data point could have its own variational parameters
The Variational Autoencoder
With this variational approximation, the per-data-point ELBO is
The first term uses the encoder distribution
Monte Carlo Estimate
Caution
The first term still involves an intractable integral, but since it is an expectation with respect to
, we can approximate it by sampling.
For any function
where
The second term is the KL divergence between the variational distribution
where
Reparameterization Trick
Caution
Sampling solves the intractable expectation, but it introduces a new problem: the sample
is drawn from a distribution whose parameters come from the encoder. If the sampling operation is treated as an opaque random step, gradients from the reconstruction term cannot flow cleanly back through , , and .
Definition (Reparameterization Trick)
The solution is to move the stochastic part into a parameter-free noise variable. First draw
and then construct
The randomness now comes from
, while is a differentiable function of the encoder outputs and . For a diagonal covariance, this is usually written as .
VAE Algorithm
To summarize, the VAE computes an approximate ELBO for each data point and uses an optimization algorithm to maximize this lower bound over the dataset. For a point
- Use the encoder
to compute the mean and covariance of . - Draw parameter-free noise
. - Use the reparameterization trick to form
. - Use the decoder
to compute the likelihood . - Estimate the reconstruction term with
. - Compute the KL term
in closed form. - Maximize the ELBO, or equivalently minimize the negative ELBO.
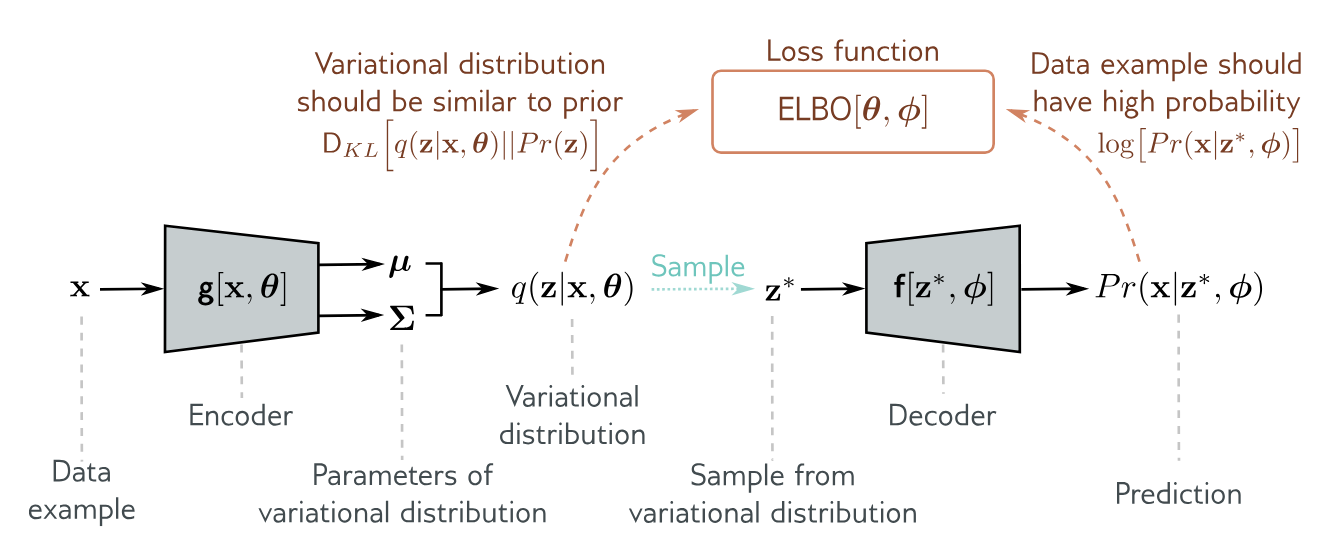
In summary:
- It is variational because it computes a Gaussian approximation to the posterior distribution.
- It is an autoencoder because it starts with a data point
, computes a lower-dimensional latent vector from this, and then uses this vector to recreate the data point as closely as possible. - In this context, the mapping from the data to the latent variable by the network
is called the encoder, and the mapping from the latent variable to the data by the network is called the decoder. - The VAE computes the ELBO as a function of both
and . To maximize this bound, we run minibatches of samples through the network and update these parameters with an optimization algorithm such as SGD or Adam. During this process, we are both moving between the colored curves in the ELBO diagram (changing ) and along them (changing ). - After training, generation uses the prior
, not the encoder. We sample and decode through .
Caution
Samples from vanilla VAEs are generally low-quality. This is partly because of the naive spherical Gaussian noise model and partly because of the Gaussian models used for the prior and variational posterior.
Tip
One trick to improve generation quality is to sample from the aggregate posterior rather than the prior:
The sum averages the encoder distributions over the dataset. It is not averaging sampled latent vectors
, and it is not collapsing the dataset to one mean and covariance. Each term is one Gaussian component with its own mean and covariance, so the aggregate posterior is a mixture of Gaussians that may be more representative of the latent regions the decoder saw during training. To sample from it, choose a data point , encode it to get , then sample from that distribution.
Modern VAEs can produce high-quality samples, but only using hierarchical priors and specialized network architecture and regularization techniques. Diffusion models can be viewed as VAEs with hierarchical priors. These also create very high-quality samples.
Sources
- Prince, S. (2023). Understanding Deep Learning. Chapter 17.