Unsupervised Learning
The defining characteristic of unsupervised learning models is that they are learned form a set of observed data
Taxonomy of Unsupervised Learning Models
A common strategy in unsupervised learning is to define a mapping between the data examples
In principle, the mapping between the observed and latent variables can be in either direction.
- Some models map from the data
to latent variables , like in k-means clustering that maps data to a cluster assignment . - Other models map from the latent
to the data , where new examples can be generated by drawing and mapping the sample to the data space .
Below are examples of some generative models that use latent variables
- Generative adversarial networks learn to generate data examples
from latent variables , using a loss that encourages the generated samples to be indistinguishable from real examples - Normalizing flows, variational autoencoders, and diffusion models are probabilistic generative models, which assigns a probability
to each data point . This will depend on the model parameters , and in training, we maximize the probability of the observed data , so the loss i s the sum of negative log-likelihoods
Tip
Since probability distributions must some to one, this implicitly reduce the probability of examples that lie far from the observed data. As well as providing a training criterion, assigning probabilities is useful in its own right; the probability on a test set can be used to compare two models quantitatively, and the probability of an example can be thresholder to determine if it belongs to the same dataset or is an outlier.
What Makes a Good Generative Model
Generative models based on latent variables should have the following properties:
- Efficient Sampling: Generating samples from the model should be computationally inexpensive and take advantage of the parallelism of modern hardware.
- High-Quality Sampling: The samples should be indistinguishable from the real data with which the model was trained.
- Coverage: Samples should represent the entire training distribution. It is insufficient to generate samples that all look like a subset of the training examples
- Well-Behaved Latent Space: Every latent variable
corresponds to a plausible data example . Smooth changes in should correspond to smooth changes in . - Disentangled Latent Space: Manipulating each dimension of
should correspond to changing an interpretable property of the data. For example, in a model of language, it might change the topic, tense, or verbosity. - Efficient Likelihood Computation: If the model is probabilistic, we would like to be able to calculate the probability of new examples efficiently and accurately.
| Model | Efficient | Sampling Quality | Coverage | Well-Behaved Latent Space | Disentangled Latent Space | Efficient Likelihood |
|---|---|---|---|---|---|---|
| GANs | n/a | |||||
| VAEs | ||||||
| Normalizing Flows | ||||||
| Diffusion Models |
Quantifying Performance
Test Likelihood
One way to compare probabilistic models is to measure their likelihood for a test dataset. It is ineffective to measure the training data likelihood because a model could assign a very high probability to each training point and low probabilities in between. The test likelihood captures how well the model generalized from the training data and also the coverage; if the model assigns a high probability to just a subset of the training data, it must assign lower probabilities elsewhere, so a portion of the test examples will have low probability.
Caution
Test likelihood is a sensible way to quantify probabilistic models, but unfortunately, it is not relevant for generative adversarial networks (which do not assign a probability) and is expensive to estimate for variational autoencoders and diffusion models (although it is possible to compute a lower bound on the log-likelihood). Normalizing flows are the only type of model for which the likelihood can be computed exactly and efficiently.
Frechet Inception Distance
This measure is intended for images and computes a symmetric distance between the distributions of generated samples and real examples. This must be approximate because it is hard to characterize either distribution (indeed, characterizing the distribution of real examples is the job of generative models in the first place). Hence, the Frechet inception distance approximates both distributions by multivariate Gaussians and estimates the distance between them using the Frechet distance.
However, it does not model the distance with respect to the original data, but rather the activations in the deepest layer of the inception classification network. These hidden units are the ones most associated with object classes, so the comparison occurs at a semantic level, ignoring the more fine-grained details of the images. This metric does not take account of diversity within classes but relies heavily on the information retained by he features in the inception network; any information discarded by the network does not contribute to the result. Some of this discarded information may still be important to generate realistic samples.
Manifold Precision/Recall
The Frechet inception distance is sensitive to both the realism of the samples and their diversity, but does not distinguish between these factors. To disentangle these qualities, we consider the overlap between the data manifold (i.e. the subset of the data space where the real examples lie) and the model manifold (i.e. where the generated samples lie).
- The precision is the fraction of model samples that fall into the data manifold, and measures the proportion of the generated samples that are realistic.
- The recall is the fraction of data examples that fall within the model manifold, and measures the proportion of the real data the model can generate.
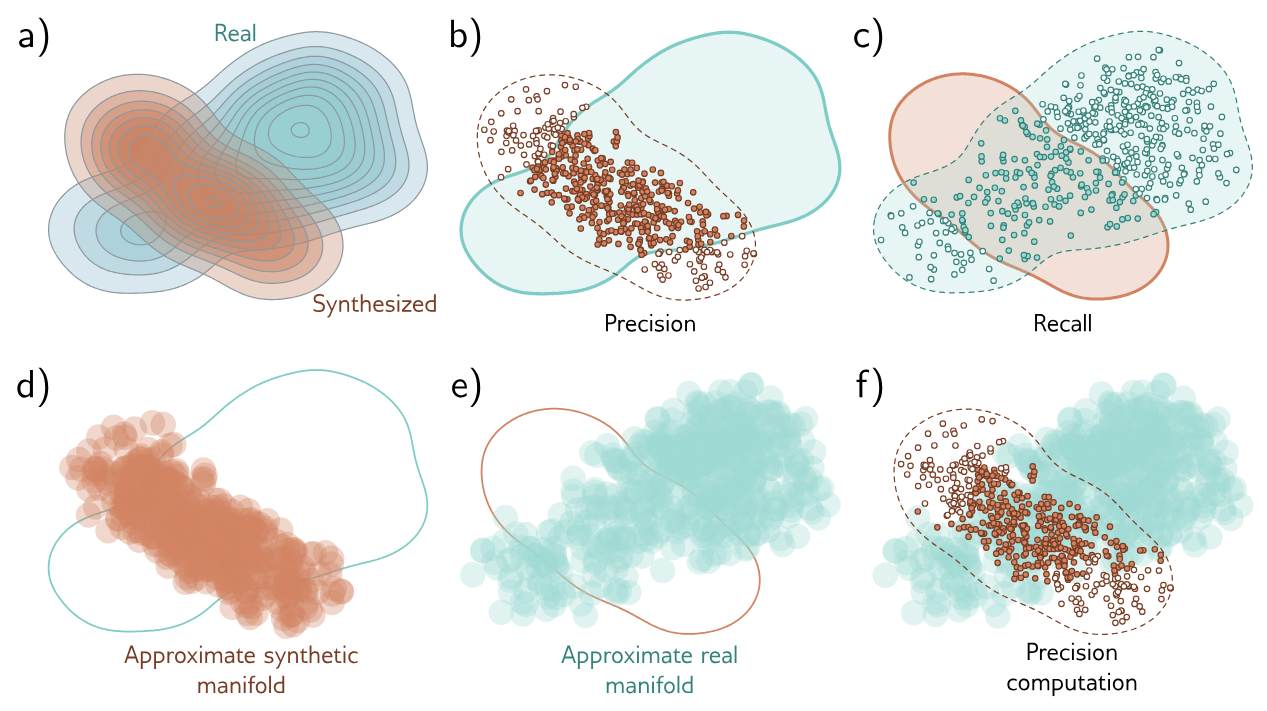
To estimate the manifold, we place a hypersphere around each data example, whose radius is the distance to the
Sources
- Prince, S. (2023). Understanding Deep Learning. Chapter 14.